
Imagine their cute little offspring!
- Query-able metadata = The ability to sort/query by several metadata fields (not just time).
- Metadata from an well established/tested source library (ExifTool)
- SQLite cross platform compatibility
- And all available for the one low price on SIFT (free!)
Being Perl, it won't be as fast as a compiled language like C/C++.
Also, at this time only .doc, .docx, .xls, .xlsx, .ppt, .pptx, .pdf and .jpg files are supported.
As a result, I'm pretty sure you wouldn't want to blindly point it at "C:\" as it could take a while/use a lot of memory.
Instead, say you found a directory of interest (eg a suspect's "naughty" directory). You could extract the metadata to the database, take a hash of the database and then send it on to another analyst for further analysis/reporting. Or you could analyse it yourself using standard SQL queries from either the "sqlite3" client or the Firefox "SQLite Manager" plugin.
As far as I know, this capability does not currently exist (at least for open source) so I think this script could prove handy for several different types of investigations. For example: fraud, e-discovery processing/culling, processing jpgs (eg exploitation).
Having a warped sense of humour, I'm calling this extraction tool "SquirrelGripper".
In Australia, to grab a bloke by his "nuts" (accidentally or on purpose or sometimes both) is also known as "the Squirrel Grip". This has been known to happen in the heat of battle/whilst tackling an opponent during a Rugby or Aussie Rules match. Thankfully, I have never had this done to me - I'd like to think I was just too quick but maybe they just couldn't find them LOL.
The idea behind the name is that "SquirrelGripper" (aka "SG") will lead analysts to the low hanging fruit right at the crux of the matter ;)
In polite company (eg client briefing), one could say that "SquirrelGripper" finds all the little nuts/nuggets of information.
By running this script an analyst will hopefully save time. Rather than having to launch the ExifTool exe multiple times for different files/metadata, they can launch this script once and then perform SQL queries for retrieving/presenting their metadata of interest.
Whilst developing this tool, I contacted some more experienced DFIR'ers for feedback. So I'd just like to say a big "ralphabetical" Thankyou to Brad Garnett, Cindy Murphy, Corey Harrell, Gerald Combs, "Girl, Unallocated" and Ken Pryor. Sorry for clogging your inboxes with my semi-organised/semi-chaotic thoughts. Having an audience for my email updates provided both structure and motivation for my thoughts.
An extra bunch of thanks to Corey Harrell (does this guy ever rest?) who was both my testing "guinea pig" and who also made some excellent suggestions. Most, if not all of his suggestions were incorporated into this latest version of SG. I can't wait to see/read how he will use it in his investigations.
Enough already! Let's get started ...
The Design
As SquirrelGripper has grown to over 1000 lines, I have decided to provide the code via my new Google Code project ("cheeky4n6monkey") and just give a general description in this blog post. Like all my scripts, it is provided "as is" and whilst I have done my best, there may still be bugs in the code. As always, perform your own validation testing before using it live.
We'll start by describing how SquirrelGripper will store metadata.
Currently, there are 9 tables in the created database - FileIndex, XLSXFiles, XLSFiles, DOCXFiles,DOCFiles, PPTXFiles, PPTFiles, PDFFiles, JPEGFiles.
FileIndex is the main index table and contains the following fields:
-"AbsFileName" (primary key) = Absolute path and filename. Used as a common key to FileIndex and other file specific tables.
-"DateTimeMetaAdded" = Date and time SquirrelGripper extracted the metadata for a file.
-"FileType" = ExifTool field indicating file type. We can use this to determine which table should contain the remaining file metadata.
-"CaseRef" = Mandatory User specified case tag string.
-"UserTag" = Optional User specified tag string. Can be used for labelling directories/files for a particular SG launch.
The 8 other tables will be used to record file type specific metadata (eg "Slides" in PPTXFiles = Number of Slides for a .pptx file). I decided to use separate tables for each file type because there are simply too many fields for a single table (over 100 in total).
Most of the metadata fields are stored as TEXT (strings) in the database. Some obvious integer fields are stored as INTs (eg Words, Slides, FileSize). GPS co-ordinates from tagged JPEGs are stored in both TEXT and REAL (decimal) format. If in doubt (eg ExifToolVersion), I made the script store the data as TEXT.
Dates are stored as TEXT in the database and I have tested that they can be processed by SQLite functions. For example, "julianday(CreateDate)" works OK. I have also been able to retrieve/sort records by date.
In the interests of everyone's sanity (including my own) I won't detail any more of the schema. You can see them yourself in the code by searching for the "CREATE TABLE" strings.
The code is structured quite similar to "exif2map.pl". We are using the File::Find package to recursively search for the handled filetypes and then we call Image::ExifTool's "GetFoundTags" and "GetInfo" functions to extract the metadata. Depending on the extracted "FileType" tag, we call the appropriate handling function (eg "ProcessPPT"). These handling functions will read selected fields and if the field is defined, the function will insert/replace the metadata into the user specified SQLite database. If the metadata does not exist, a "Not Present" string will be inserted into the table instead.
Selections of metadata fields were made
For example, MS Office 2007+ files have a variable list of "Zip" fields which I thought was of limited value so the script doesn't store these. However, the main fields such as "FileName", "CreateDate", "FileModifyDate" etc. are all included.
Having said that, if you think SquirrelGripper should include a particular field that I've left out, please let me know.
Installing SquirrelGripper
The Image::ExifTool Perl package is already installed on SIFT. We have previously used it in our "exif2map.pl" script. However due to some internal label changes to ExifTool, we need to grab the latest version (v8.90) for our script. We can do this on SIFT by typing: "sudo cpan Image::ExifTool".
The last few posts have also detailed our travels with Perl and SQLite. We have been using the DBI Perl package to interface with SQLite databases. So if you haven't already done it, grab the latest DBI package from CPAN by typing: "sudo cpan DBI".
Next, you can download/unzip/copy "squirrelgripper.pl" (from here) to "/usr/local/bin" and make it executable (by typing "sudo chmod a+x /usr/local/bin/squirrelgripper.pl")
Now you should be ready to run SquirrelGripper on SIFT in all its glory.
To run on Windows, install ActiveState Perl and use the Perl Package Manager to download the ExifTool package (v8.90). DBI should already be installed. Next, copy the "squirrelgripper.pl" script to the directory of your choice.
You should now be able to run SG at the command prompt by typing something like:
"perl c:\squirrelgripper.pl -newdb -db nutz2u.sqlite -case caseABC -tag fraud-docs -dir c:\squirrel-testdata\subdir1"
See next section for what each of the arguments mean.
Running SquirrelGripper
For this test scenario, I have various .doc, .docx, .xls, .xlsx, .ppt, .pptx, .pdf files in the "/home/sansforensics/squirrel-testdata/subdir1" directory.
I have also copied various .jpg files to the "/home/sansforensics/squirrel-testdata/subdir2" directory
It is assumed that a new database will be created for each case. However, the same database can be also used for multiple iterations of the script. Just FYI - you can get a help/usage message by typing "squirrelgripper.pl -h"
The script recursively searches thru sub-directories so please ensure you've pointed it at the right level before launching. It is also possible to mark different sub-directories with different case tags. eg Launch script with one directory using the case tag "2012-04-18-caseA-companyA". Then launch the script a second time pointing to another directory using the case tag "2012-04-18-caseA-companyB". SG can also handle multiple -dir arguments in case you need to extract data from more than one directory (eg "-dir naughty/pics -dir naughty/docs"). If a "-tag" argument is also specified, it will apply to files from both directories.
The first example uses "-newdb" to create the "nutz2u.sqlite" database in the current directory. It also tags all "subdir1" files with the "fraud-docs" user tag (you can see the "UserTag" value in the "FileIndex" table). Currently, the "-db", "-case" and "-dir" arguments are mandatory.
Note: the -dir directory can be an absolute path or a relative one.
squirrelgripper.pl -newdb -db nutz2u.sqlite -case caseABC -tag fraud-docs -dir /home/sansforensics/squirrel-testdata/subdir1/
The output looks like:
squirrelgripper.pl v2012.05.18
Assuming /home/sansforensics/squirrel-testdata/subdir1/ is an absolute path
Directory entry for processing = /home/sansforensics/squirrel-testdata/subdir1/
Now processing /home/sansforensics/squirrel-testdata/subdir1/excel2k7-Book1.xlsx
/home/sansforensics/squirrel-testdata/subdir1/excel2k7-Book1.xlsx inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/excel2k7-Book1.xlsx inserted into XLSXFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/doj-forensic-examination-dig-evidence-law-enforcers-guide-04-199408.pdf
/home/sansforensics/squirrel-testdata/subdir1/doj-forensic-examination-dig-evidence-law-enforcers-guide-04-199408.pdf inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/doj-forensic-examination-dig-evidence-law-enforcers-guide-04-199408.pdf inserted into PDFFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/word2k7.docx
/home/sansforensics/squirrel-testdata/subdir1/word2k7.docx inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/word2k7.docx inserted into DOCXFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/08-069208CaseReport.doc
/home/sansforensics/squirrel-testdata/subdir1/08-069208CaseReport.doc inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/08-069208CaseReport.doc inserted into DOCFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/acme_report.pdf
/home/sansforensics/squirrel-testdata/subdir1/acme_report.pdf inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/acme_report.pdf inserted into PDFFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/Windows Passwords Master 1.5 Handout - Jesper Johansson.ppt
/home/sansforensics/squirrel-testdata/subdir1/Windows Passwords Master 1.5 Handout - Jesper Johansson.ppt inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/Windows Passwords Master 1.5 Handout - Jesper Johansson.ppt inserted into PPTFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/excel2k7-Book2.xlsx
/home/sansforensics/squirrel-testdata/subdir1/excel2k7-Book2.xlsx inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/excel2k7-Book2.xlsx inserted into XLSXFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir1/Powerpoint2k7.pptx
/home/sansforensics/squirrel-testdata/subdir1/Powerpoint2k7.pptx inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir1/Powerpoint2k7.pptx inserted into PPTXFiles table
sansforensics@SIFT-Workstation:~$
The second call assumes the "nutz2u.sqlite" database already exists and tags all "subdir2" files with the "fraud-pics" tag.
squirrelgripper.pl -db nutz2u.sqlite -case caseABC -tag fraud-pics -dir /home/sansforensics/squirrel-testdata/subdir2
The output looks like:
squirrelgripper.pl v2012.05.18
Assuming /home/sansforensics/squirrel-testdata/subdir2 is an absolute path
Directory entry for processing = /home/sansforensics/squirrel-testdata/subdir2
Now processing /home/sansforensics/squirrel-testdata/subdir2/GPS2.jpg
lat = 41.888948, long = -87.624494
/home/sansforensics/squirrel-testdata/subdir2/GPS2.jpg : No GPS Altitude data present
/home/sansforensics/squirrel-testdata/subdir2/GPS2.jpg inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir2/GPS2.jpg inserted into JPEGFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir2/Cheeky4n6Monkey.jpg
/home/sansforensics/squirrel-testdata/subdir2/Cheeky4n6Monkey.jpg : No GPS Lat/Long data present
/home/sansforensics/squirrel-testdata/subdir2/Cheeky4n6Monkey.jpg : No GPS Altitude data present
/home/sansforensics/squirrel-testdata/subdir2/Cheeky4n6Monkey.jpg inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir2/Cheeky4n6Monkey.jpg inserted into JPEGFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir2/GPS_location_stamped_with_GPStamper.jpg
lat = 41.888948, long = -87.624494
/home/sansforensics/squirrel-testdata/subdir2/GPS_location_stamped_with_GPStamper.jpg : No GPS Altitude data present
/home/sansforensics/squirrel-testdata/subdir2/GPS_location_stamped_with_GPStamper.jpg inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir2/GPS_location_stamped_with_GPStamper.jpg inserted into JPEGFiles table
Now processing /home/sansforensics/squirrel-testdata/subdir2/wheres-Cheeky4n6Monkey.jpg
lat = 36.1147630001389, long = -115.172811
/home/sansforensics/squirrel-testdata/subdir2/wheres-Cheeky4n6Monkey.jpg : No GPS Altitude data present
/home/sansforensics/squirrel-testdata/subdir2/wheres-Cheeky4n6Monkey.jpg inserted into FileIndex table
/home/sansforensics/squirrel-testdata/subdir2/wheres-Cheeky4n6Monkey.jpg inserted into JPEGFiles table
sansforensics@SIFT-Workstation:~$
SquirrelGripper has also been similarly tested using ActiveState Perl v5.14.2 on Win XP by myself and Corey Harrell has also tested it using ActiveState Perl v5.12 on Windows 7 (32/64). Please note however, that the majority of my testing was done on SIFT v2.12 and Perl 5.10.0.
Once the metadata has been extracted to the SQLite database we can use SQL queries to find specific files of interest. This can be done via the "sqlite3" client and/or more easily via the Firefox "SQLite Manager" plugin.
Extracting SquirrelGripper results
So now we have our SQLite database chock full of metadata - how can we search it?
We need some basic SQLite commands which we can learn here.
W3Schools and Wikipedia also have some useful general information on SQL queries.
For our first example query we will be finding pictures from a particular camera model and ordering the results by date/time of the original.
Building upon the previous section, we have opened the "nutz2u.sqlite" database by using the Firefox "SQLite Manager" plugin on SIFT.
To do this - open Firefox on SIFT, under the "Tools" menu, select "SQLite Manager" to launch.
Then under the "Database" menu, select "Connect Database", browse to the user specified database (eg "nutz2u.sqlite") and press the "Open" button. Click on the "FileIndex" table tree item on the left hand side and then look under the "Browse & Search" tab. You should now see something like:
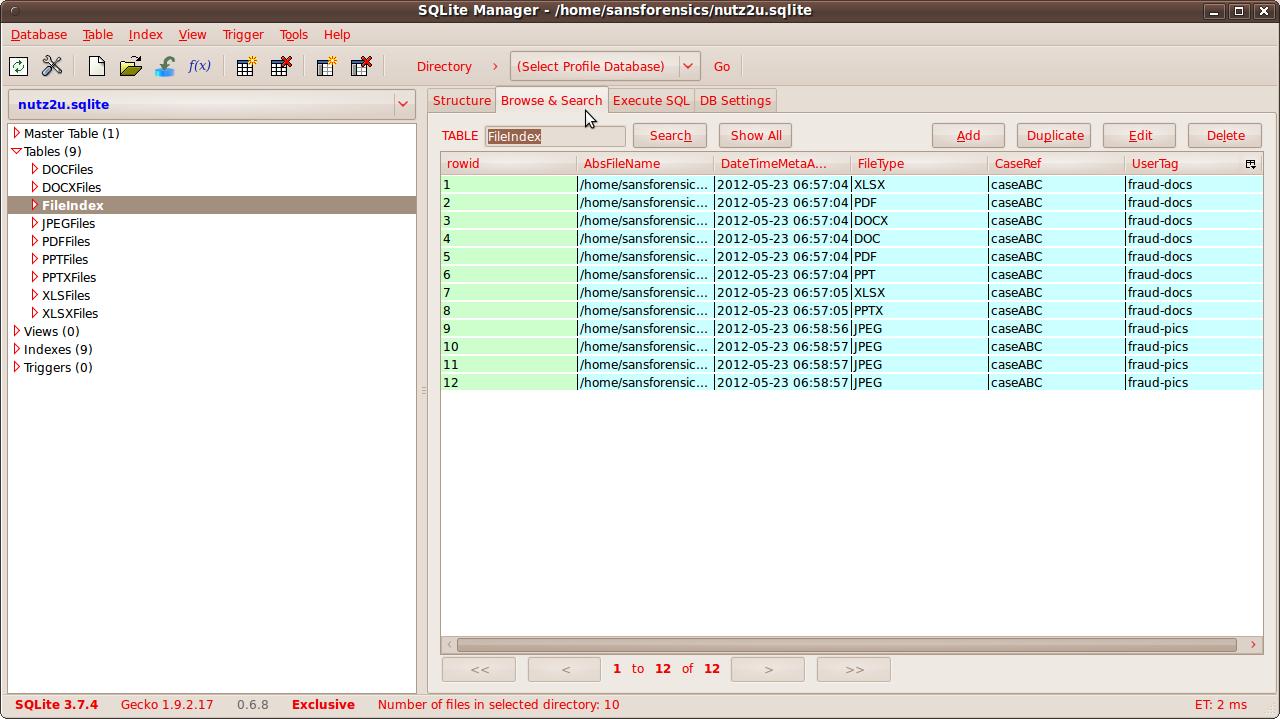 |
| nutz2u.sqlite's FileIndex Table |
If we now click on the "JPEGFiles" table tree item and look under the "Browse & Search" tab, we can see which jpeg files had their metadata extracted:
 |
| nutz2u.sqlite's JPEGFiles Table |
Note: For the file specific tables, you will probably have to use the scroll bar to see all of the fields. Not shown in the pic above are the "Model" and "DateTimeOriginal" fields. We will be using these fields in our SQL query.
To execute a query against the JPEGFiles table, we click on the "Execute SQL" tab and then enter in the following:
SELECT * FROM JPEGFiles WHERE Model='Canon PowerShot SX130 IS' ORDER BY DateTimeOriginal;
We then press the "Run SQL" button and we see that we have found two jpegs that meet our search criteria:
 |
| nutz2u.sqlite's SQL Search Results |
Similarly, we can run other queries against the database such as:
Finding .docs by same author and sorting by page count:
SELECT * FROM DOCFiles WHERE Author='Joe Friday' ORDER BY PageCount;
Sorting Powerpoint files by Revision Number:
SELECT * FROM PPTFiles ORDER BY RevisionNumber;
Finding all "fraud-pics" user tagged .JPEGs:
SELECT * FROM JPEGFiles, FileIndex WHERE JPEGFiles.AbsFileName=FileIndex.AbsFileName AND FileIndex.UserTag='fraud-pics';
Finding the LastModified time and the user responsible (for .xlsx files) BEFORE a given date/time:
SELECT LastModifiedBy, ModifyDate from XLSXFiles where DATETIME(ModifyDate) < DATETIME('2012-05-01 06:36:54')
Note: We are using the SQLite DATETIME function to convert our string date into a format we can perform comparisons with.
Finding the Filename and Keywords (for .pptx files) where the Keywords contains "dea". This will find keywords such as "death" "deal" "idea". The % represents a wildcard:
SELECT FileName, Keywords from PPTXFiles where Keywords LIKE '%dea%'
Finding the Filename and Template names used (for .doc files) when the Template name starts with "Normal.dot":
SELECT FileName, Template FROM DOCFiles WHERE Template LIKE 'Normal.dot%'
Find Unique Company names by performing a UNION of each table's Company fields. For more information on the UNION keyword see here.
SELECT Company FROM DOCFiles UNION SELECT Company FROM DOCXFiles UNION SELECT Company FROM XLSXFiles UNION SELECT Company FROM XLSFiles UNION SELECT Company FROM PPTXFiles UNION SELECT Company FROM PPTFiles
Finding the Filename and GPS Longitude (for .jpg files) where the GPS Longitude is less than "-115.0":
SELECT FileName, GPSLongitude FROM JPEGFiles WHERE GPSLongitude < '-115.0'
There are LOTS more ways of querying the database because there's a shedload of other fields we can use. Check out the script code (search for "CREATE TABLE") or create your own example database (using SG) for more details on what metadata fields are being extracted. Where possible, I have used the same field names as the ExifTool exe prints to the command line.
Final Words
We have written a Perl script ("squirrelgripper.pl") to extract file metadata into an SQLite Database. We have also shown how to perform some basic SQL queries against that database.
In total, for the .doc, .docx, .xls, .xlsx, .ppt, .pptx, .pdf, .jpeg file types there were over 100 fields to extract. Whilst I double-checked my script, it is possible I've made some errors/overlooked something. It is also possible to process other file types (eg EXE, DLL) but I thought I would wait for further feedback/specific requests before continuing.
UPDATE: Just had this thought - If/when I do add the EXE & DLL functionality, SquirrelGripper could also be used for locating known Malware/indicators of compromise as well. I've created a monster!
I suspect there will be some commonly used SQL queries across certain types of investigations. So analysts could build up a standard set of queries to run across multiple cases of the same type. That could save analysts time / help narrow down files of interest.
If you found this script useful and/or you have any questions, please drop me a Tweet / email / leave a comment. The more I know about if/how forensicators are using SquirrelGripper - the better I can make it. Now that the basic framework is in place, it should be pretty quick to add new fields/file types so long as they are supported by the Image::ExifTool package (v8.90).